Special note: we’re teaching a fully updated part 1, in person, for seven weeks from Oct 30, 2017, at the USF Data Institute. See the course page for details and application form.
When we launched course.fast.ai we said that we wanted to provide a good education in deep learning. Part 1 of the course has now been viewed by tens of thousands of students, introducing them to nearly all of today’s best practices in deep learning, and providing many hours of hands-on practical coding exercises. We have collected some stories from graduates of part 1 on our testimonials page.
Today, we are launching Part 2: Cutting Edge Deep Learning for Coders. These 15 hours of lessons take you from part 1’s best practices, all the way to cutting edge research. You’ll learn how to:
- Read and implement the latest research papers (even if you don’t have a math background)
- Build a state of the art neural translation system
- Create generative models for art, super resolution, segmentation, and more (including generative adversarial networks)
- Apply deep learning to structured data and time series (such as for logistics, marketing, predictive maintenance, and fraud detection)
- …and much more.
We believe that we have created a unique path to deep learning expertise, and many of our students have shown what’s possible, such as:
- Sara Hooker, who only started coding 2 years ago, and is now part of the elite Google Brain Residency
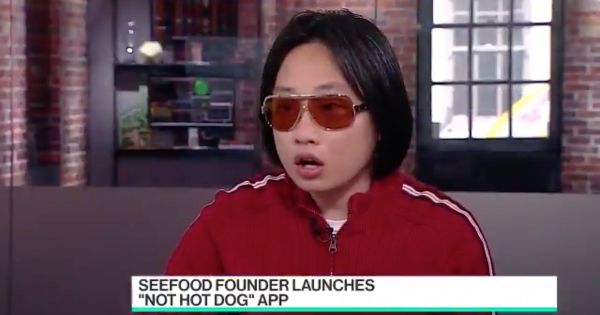
- Tim Anglade, who used Tensorflow to create the Not Hot Dog app for HBO’s Silicon Valley, leading Google’s CEO to tweet “our work here is done”
- Gleb Esman, who created a new fraud product for Splunk using the tools he learnt in the course, and was featured on Splunk’s blog
- Jacques Mattheij, who built a robotic system to sort two tons of lego
- Karthik Kannan, founder of letsenvision.com, who told us “Today I’ve picked up steam enough to confidently work on my own CV startup and the seed for it was sowed by fast.ai with Pt1. and Pt.2”
- Matthew Kleinsmith and Brendon Fortuner, who in 24 hours built a system to add filters to the background and foreground of videos, giving them victory in the 2017 Deep Learning Hackathon.
The prerequisites are that you’ve either completed part 1 of the course, or that you are already a confident deep learning practictioner who is comfortable implementing and using:
- CNNs (including resnets)
- RNNs (including LSTM and GRU)
- SGD/Adam/etc
- Batch normalization
- Data augmentation
- Keras and numpy
What we cover
The course covers a lot of territory - here’s a brief summary of what you’ll learn in each lesson:
Lesson 8: Artistic Style
We begin with a discussion of a big change compared to part 1: from Theano to Tensorflow. You’ll learn about some of the exciting new developments in Tensorflow that have led us to the decision to make this change. We’ll also talk about a major project we highly recommend: build your own deep learning box!
We’ll also talk about how to approach one of the biggest challenges in this part of the course: reading acadmic papers. Don’t worry, it’s not as terrifying as it first sounds—especially once you know some of our little tricks.
Then, we start our deep dive into creative and generative applications, with artistic style transfer. You’ll be able to create beautiful and interesting images even if your artistics skills are as limited as Jeremy’s… :)

Lesson 9: Generative Models

We’ll learn about the extraordinarily powerful and widely useful technique of generative models. These are models that don’t just spit out a classification, but create a whole new image, sound, etc. They can be used, for example, with images, to:
- Improve photos (colorization, noise removal, increase resolution, etc)
- Create art
- Find and segment (localize) objects
- and much more…
We’ll try using this approach for super resolution (i.e. increasing the resolution of an image), and then you’ll get to try building your own system for rapidly adding the style of any artist to your photos. Have a look at the image on the right - the top very low resolution image has been input to the algorithm (see for instance the very pixelated fingers), and the bottom image has been created automatically from that!
Lesson 10: Multi-modal & GANs
A surprising result in deep learning is that models created from totally different types of data, such as text and images, can learn to share a consistent feature space. This means that we can create multi-modal models; that is, models which can combine multiple types of data. We will show how to combine text and images in a single model using a technique called DeVISE, and will use it to create a variety of search algorithms:
- Text to image (which will also handle multi-word text descriptions)
- Image to text (including handling types of image we didn’t train with)
- And even image to image!
Doing this will require training a model using the whole imagenet competition dataset, which is a bigger dataset than we’ve used before. So we’re going to look at some techniques that make this faster and easier than you might expect.
We’re going to close our studies into generative models by looking at generative adversarial networks (GANs), a tool which has been rapidly gaining in popularity in recent months, and which may have the potential to create entirely new application areas for deep learning. We will be using them to create entirely new images from scratch.
Lesson 11: Memory Networks
We’ve covered a lot of different architectures, training algorithms, and all kinds of other CNN tricks during this course—so you might be wondering: what should I be using, when? The good news is that other folks have wondered that too, and have provided some great analyses of the pros and cons of various techniques in practice. We’ll be taking a look at a few highlights of these papers today.
Then we’re going to learn to GPU accelerate algorithms by taking advantage of Pytorch, which provides an interface that’s so similar to numpy that often you can move your algorithm onto the GPU in just an hour or two. In particular, we’re going to try to create the first (that we know of) GPU implementation of mean-shift clustering, a really useful algorithm that deserves to be more widely known.
To close out the lesson we will implement the heavily publicized “Memory Networks” algorithm, and will answer the question: does it live up to the hype?
Lesson 12: Attentional Models
It turns out that Memory Networks provide much of the key foundations we need to understand something which have become one of the most important advances in the last year or two: Attentional Models. These models allow us to build systems that focus on the most important part of the input for the current task, and are critical, for instance, in creating translation systems (which we’ll cover in the next lesson).
Lesson 13: Neural Translation
One application of deep learning that has progressed perhaps more than any other in the last couple of years is Neural Machine Translation. In late 2016 it was implemented by Google in what the New York Times called The Great A.I. Awakening. There’s a lot of tricks needed to reach Google’s level of translation capability, so we’ll be doing a deep dive in this lesson to learn nearly all the tricks used by state of the art systems.
Next up, we’ll learn about Densenets, which in July 2017 were awarded the CVPR Best Paper award, and have been shown to provide state of the art results in computer vision, particularly with small datasets. They are very similar to resnets, but with one key difference: the branches in each section are combined through concatenation, rather than addition. This apparently minor change makes a big difference in how they learn. We’ll also be using this technique in the next lesson to create a state of the art system for image segmentation.
Lesson 14: Time Series & Segmentation
Deep learning has generally been associated with unstructured data such as images, language, and audio. However it turns out that the structured data found in the columns of a database table or spreadsheet, where the columns can each represent different types of information in different ways (e.g. sales in dollars, area as zip code, product id, etc), can also be used very effectively by a neural network. This is equally true if the data can be represented as a time series (i.e. the rows represent different times or time periods).
In particular, what we learnt in part 1 about embeddings can be used not just for collaborative filtering and word encodings, but also for arbitrary categorical variables representing products, places, channels, and so forth. This has been highlighted by the results of two Kaggle competitions that were won by teams using this approach. We will study both of these datasets and competition winning strategies in this lesson.
Finally, we’ll look at how the Densenet architecture we studied in the last lesson can be used for image segmentation - that is, exactly specifying the location of every object in an image. This is another type of generative model, as we learnt in lesson 9, so many of the basic ideas from there will be equally applicable here.